AMAZON REDSHIFT. 정렬 키(SORT KEY)의 이해
AWS정렬 키에서 지정한 열의 순서로 데이터는 정렬된 상태로 테이블에 저장된다. 데이터를 정렬된 형태로 저장하면 읽어야할 데이터를 줄임으로써 쿼리
성능을 향상시킬 수 있다. 예를 들어, 고객번호를 정렬 키로 데이터를 저장한 상태에서, 고객번호 30에서 50 사이의 고객 정보를 조회하고자 하는 상황이라고 하자. 이때 데이터를 읽어가다 고객 번호가 50보다 큰 데이터가 나타나기 시작하면, 나머지 데이터를 다 읽지 않아도 읽기 작업을 멈춰도 된다. 이렇게 읽어야할 데이터를 줄여 성능 향상을 기대할 수 있게된다(실제론 이렇게 동작하지 않는다. 이해를 높기위한 설명으로 실제 동작 방식은 아래에서 정리한다).
일반적인 OLTP 워크로드를 처리하는 관계형 데이터베이스와 달리 Amazon Redshift는 인덱스의 개념이 없기 때문에, 정렬 키는 거의 유일하게 읽어야할 데이터를 줄여줄 수 있는 수단이다. 그래서 성능 관점에서 봤을 때 가장 중요한 몇 가지 요소 중 하나라고 생각한다. 잘만 쓰면 성능을 몇 배로 높일 수 있다. 특히 대용량 테이블에서는 그 효과는 더욱 커진다.
여기서는 정렬 키의 종류와 내부 구조에 대한 내용을 정리한다.
복합(Compound) 정렬 키

그림 출처: Redshift Sort Keys – Choosing Best Sort Style
복합 정렬 키는 엑셀에서의 데이터 정렬을 생각하면 된다. 정렬 키로 지정한 첫 번째 열로 먼저 정렬을 한다. 그리고 첫 번째 열 중 같은 값들은 두 번째 열로 다시 정렬하여 저장한다. Amazon Redshift는 열 단위로 데이터를 1MB 블록으로 저장하는데, 각 블록의 최소, 최대 값을 저장해 놓고 해당 블록을 읽을지 말지를 결정한다. 앞의 고객번호 예제를 이야기 하지면, 정확하게는 고객번호가 30에서 50사이의 블록만 읽으면 읽기 작업을 완료할 수 있다.
위 그림의 예제는 c_customer_id와 c_country_id 순서로 복합 정렬 키를 만들었을 때 블록을 그린것이다. 여기서 c_customer_id = 1인 데이터를 요청하면, 첫 번째 블록만 읽어서 사용자 요청에 응답할 수 있다. 나머지 데이터는 안 읽어도 되므로 처리 시간을 단축할 수 있는 것이다. 하지만 두 번째 정렬 키인 c_country_id로는 읽어야할 데이터를 줄일 수가 없다. 만약 c_country_id = 1인 데이터를 요청하면, 4개의 블록을 모두 읽어야 되므로 성능적 이득은 없다.
이상 복합 정렬 키의 특징을 정리해보면 다음과 같다.
WHERE 절에 정렬 키의 첫 번째 열로 데이터를 제한하는 부분이 있으면 읽을 데이터를 줄여준다
정렬 키의 첫 번째 열의 카디널리티 높으면 좋다.
WHERE 절에 정렬 키의 첫 번째 열이 없다면 읽어야 할 데이터를 줄여주지 못 한다
GROUP BY, ORDER BY 와 같이 정렬이 필요한 작업에 이점이 있다
인터리브(Interleaved) 정렬 키

그림 출처: Redshift Sort Keys – Choosing Best Sort Style
인터리브 정렬 키는 한마디로 뭐다라고 표현하기가 참 힘들다. 많은 문서에서 대부분 다음과 같이 설명한다. 먼저 살펴보자.
인터리브 정렬 키는 정렬 키에서 각 열, 즉 열의 하위 집합에 똑같은 가중치를 부여합니다 - Amazon Redshift 정렬 키 선택
인터리브 정렬 키를 정확하게 이해하기 위해서는 z order curve 혹은 z order index 이런 것들을 공부하면 보다 그 구조를 잘 알 수 있게된다. 자세한 내용은 추후에 정리해 보기로 하고, 여기서는 앞의 그림을 통해 인터리브 정렬 키는 어떻게 읽을 데이터를 줄여가는지 살펴보고, 어떤 상황에서 인터리브 정렬 키를 쓰면될지 정리해보자.
먼저 복합 정렬 키와 인터리브 정렬 키의 가장 큰 차이는 첫 번째 정렬 키 열이라도 동일한 값이 여러 데이터 블록에 나뉘어 저장된다는 것이다. 대신 두 번째 정렬 키 열로도 같은 가중치로 데이터 블록이 나뉘어 저장된다. 쉽게 이야기하면, 첫 번째 정렬 키의 일부분과 두 번째 정렬 키의 일부분 부분의 조합으로 데이터 블록을 구성한다. 그래서 정렬 키의 첫 번째 열이든, 두 번째 열이든 상관없이 읽어야할 데이터를 줄여줄 수 있다.
몇 가지 예제로 조건별 읽어야 할 데이터 블록의 위치를 살펴보자. 여기 예제에서도 동일하게 c_customer_id 열과 c_country_id 열의 순서로 인터리브 정렬 키를 정의했다고 가정한다.
WHERE c_customer_id = 3 AND c_country_id = 104

WHERE c_customer_id = 3

WHERE c_country_id = 104
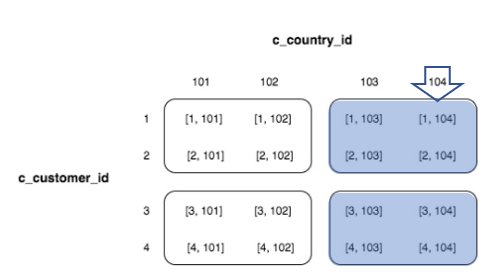
이렇게 살펴본바로 인터리브 정렬 키의 가장 큰 특징은 정렬 키를 정의할 때 선언한 두 번째 열로도 읽어야할 데이터를 줄일 수 있다는 것이다.
특징
정렬 키를 이루는 열 순서에 상관없이 WHERE 절에 나타나면 잘 동작한다.
GROUP BY, ORDER BY 이점이 없다(전체 블록을 다 읽어 정렬해봐야 한다).
VACUUM 작업시 실행 시간이 (매우) 길어질 수 있다.
예제
-- 단일 열에 복합 정렬 키 create table customer ( c_custkey integer not null sortkey, c_name varchar(25) not null, c_address varchar(25) not null, c_city varchar(10) not null, c_nation varchar(15) not null, c_region varchar(12) not null, c_phone varchar(15) not null, c_mktsegment varchar(10) not null ) -- 여러 열에 복합 정렬 키 create table customer_comp ( c_custkey integer not null, c_name varchar(25) not null, c_address varchar(25) not null, c_city varchar(10) not null, c_nation varchar(15) not null, c_region varchar(12) not null, c_phone varchar(15) not null, c_mktsegment varchar(10) not null ) COMPOUND SORTKEY (c_custkey, c_name) -- 여러 열에 인터리브 정렬 키 create table customer_inter ( c_custkey integer not null, c_name varchar(25) not null, c_address varchar(25) not null, c_city varchar(10) not null, c_nation varchar(15) not null, c_region varchar(12) not null, c_phone varchar(15) not null, c_mktsegment varchar(10) not null ) INTERLEAVED SORTKEY (c_custkey, c_name, c_phone)
정렬 키 정보(시스템 테이블)
select * from SVV_TABLE_INFO where "table" in ('customer_inter','customer_comp', 'customer') select * from PG_TABLE_DEF where tablename in ('customer_inter','customer_comp', 'customer')
'AWS' 카테고리의 다른 글
| AMAZON REDSHIFT. VACUUM 명령 (0) | 2018.09.19 |
|---|---|
| AMAZON REDSHIFT. COPY 명령2 - 최적화 (0) | 2018.08.17 |
| AMAZON REDSHIFT. COPY 명령1 - 기본내용 (0) | 2018.08.16 |
| AMAZON REDSHIFT. 데이터 압축3 - 관리 (0) | 2018.08.14 |
| AMAZON REDSHIFT. 데이터 압축2 - 압축 수행 (0) | 2018.08.14 |